An aside/apology: while doing the literature search, we somehow completely missed Rajarshi's blog post from 2012 (http://blog.rguha.net/?p=997). This is really embarrassing. Sorry Rajarshi...
Let's start with the pre-requisites. You need an installation of at least v3.4.0 of KNIME (released July 2017). That installation should have the KNIME text mining extensions and the Python Integration version that supports Python 2 and Python 3. At the time of writing these are both in KNIME Labs. It's not a bad idea to have the RDKit nodes installed too (these are available in the KNIME Community Extensions section in the "Install KNIME Extensions" dialog). You also need to have the Python extension properly configured, I covered this in a post on the KNIME blog: https://www.knime.com/blog/setting-up-the-knime-python-extension-revisited-for-python-30-and-20. The condo environment you are using from KNIME should have both the RDKit and CheTo installed from the rdkit channel (see the CheTo installation instructions above).
phew... now we're ready to go. Here's a screenshot of the sample workflow for doing chemical topic modeling:

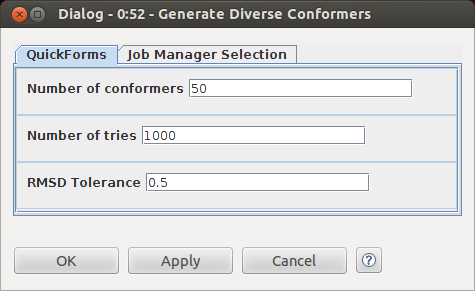
The table reader at the beginning brings in a set of a couple hundred molecules taken from 12 ChEMBL documents. The real work is done in the "fingerprint and do LDA" wrapped metanode, which expects an input table that has a column named "smiles" that contains SMILES. We won't get into the details of the contents of this node here, but if you configure the node (double click or right click and "configure") you'll get a dialog which allows you to change the important parameters:

Executing the node, which can take a while since it's not currently very well optimized, gives you two tables. The first has the individual molecules assigned to topics:

and the second has the bits that define the topics themselves, including Nadine's very nice depictions of the fingerprint bits:

The GroupBy nodes provide a summary of the number of documents each topic shows up in as well as the number of topics that are identified in each document. This last was one of the validation metrics that we used in the paper; here's what we get with the sample data set:

There's a lot more detail in the paper about what this all means and what you might do with it; the goal for this post was to provide a very quick overview of how to do the analysis and look at the results inside of KNIME. I hope I was successful with that.
The workflow itself is on the KNIME public examples server, you find that in KNIME by logging into the examples server and then navigating to Examples/99_Community/03_RDKit/08_Chemical_Topic_Modeling:



_026.png)


+_020.png)








_007.png)